tuple的处理流程
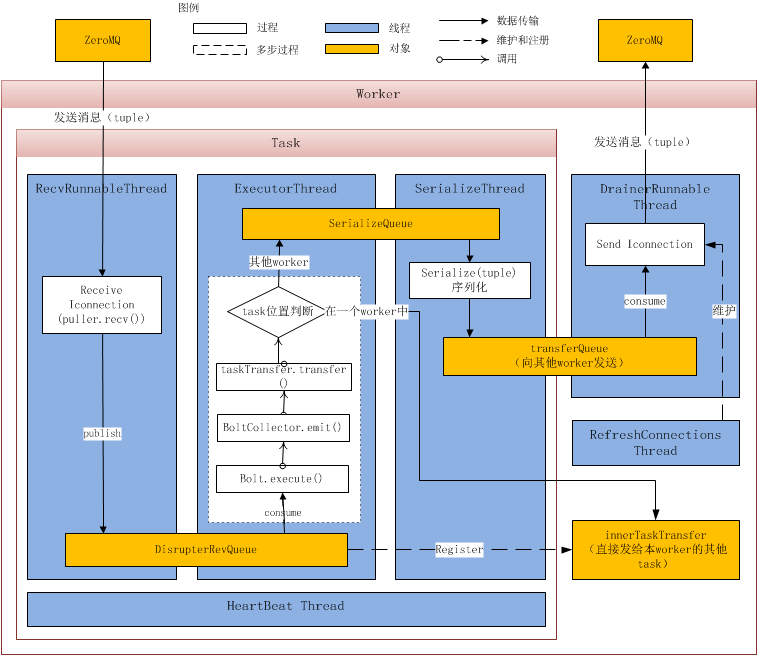
Tuple的处理流程图如图1所示:
tuple的发送
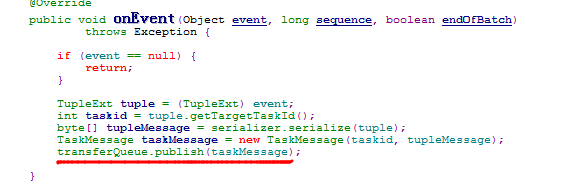
首先Bolt在发射一个tuple的时候是调用OutputCollector(位置:backtype.storm.task)的emit()或者emitDirect()方法,这个OutputCollector一般定义在Bolt类中用于tuple的发送,OutputCollector.emit()(emitDirect()类似,后面不再赘述)会调用一个IOutputCollector接口的emit()方法,例如BoltCollector等类继承了这个接口。当Topology部署到服务端后,其实就是调用了BoltCollector的emit()方法,它由调用了boltEmit()方法,这里会先处理一些acker相关逻辑,然后调用taskTransfer进行tuple的发送。

taskTransfer是一个TaskTransfer对象,这个类是task发送tuple的入口。transfer()中会首先对于目标task进行判断,如果是worker的内部task则将tuple放入innerTaskTransfer中属于这个taskid的发送队列,否则放入serializeQueue队列。这两者都是DisruptorQueue对象,在这个队列中,会定时批量处理其中的对象(consumeBatchWhenAvailable()和consumeBatchToCursor())。
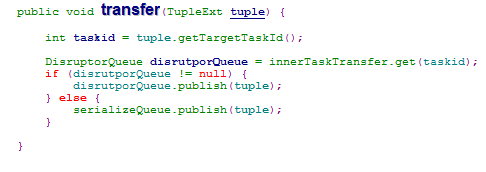
innerTaskTransfer是一个workerdata中生成的map结构,建立了taskid和worker内部发送队列的对应关系。它在BaseExecutors类被引用,在BoltExecutors或者SpoutExecutors对象生成时会建立和它的对应关系,在BaseExecutors对象构造时会把本task的接受队列disruptorRecvQueue加入本worker的innerTaskTransfer中。这样worker内部发送tuple时会直接放入目标task的接受队列中而不必调用socket方法。

TaskTransfer类会维护一个serializeQueue队列和一个serializeThread线程。serializeThread会不断地调用serializeQueue的consumeBatchWhenAvailable(this)方法,这会促使其中的tuple被serializeThread.onEvent()处理。在onEvent()中, tuple会被序列化并放入对应workerData的transferQueue中交给worker处理。

到了worker这里,worker中的workerData里维护一个transferQueue来保存需要发送的tuple,同时worker会执行一个DrainerRunable线程负责发送(调用transferQueue的consumeBatchWhenAvailable()方法来启动自己的DrainerRunable.onEvent()),底层是利用了IConnection进行发送。这里不同的worker之间是在topology启动的时候就已经建立zeroMQ的链接,同时通过RefreshConnections线程(backtype.storm.messaging.IContext)不断地更新和维护。
总结一些Twitter Storm对于tuple的处理/创建过程:
- Bolt创建一个tuple。
- Worker把tuple, 以及这个tuple要发送的地址(task-id)组成一个对象(task-id, tuple)放进待发送队列(LinkedBlockingQueue).
- 一个单独的线程(async-loop所创建的线程)会取出发送队列里面的每个tuple来处,Worker创建从当前task到目的task的zeromq连接。序列化这个tuple并且通过这个zeromq的连接来发送这个tuple。
tuple的接受和处理
每个worker在实例化的时候都会生成对应的task,而后task.mk_executors()会根据类型分别创建新的bolt或者spout(BoltExecutors或SpoutExecutors),Executors是独立的线程在运行。
以BoltExecutors(com.alibaba.jstorm.task.execute)为例,它的线程函数中有两个工作:监控是否超时并返回acker一个fail信号,激活接受队列(disruptorRecvQueue,DisruptorQueue对象)消耗队列中的项。
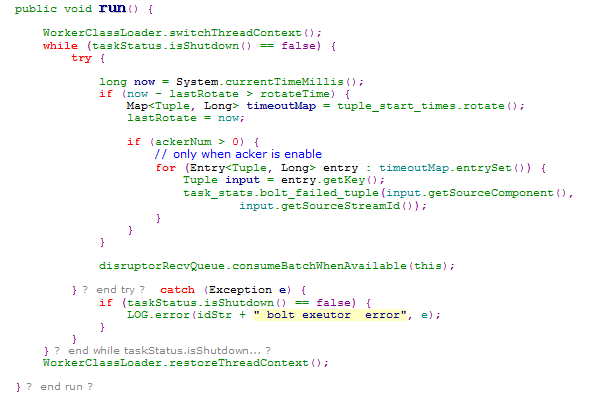
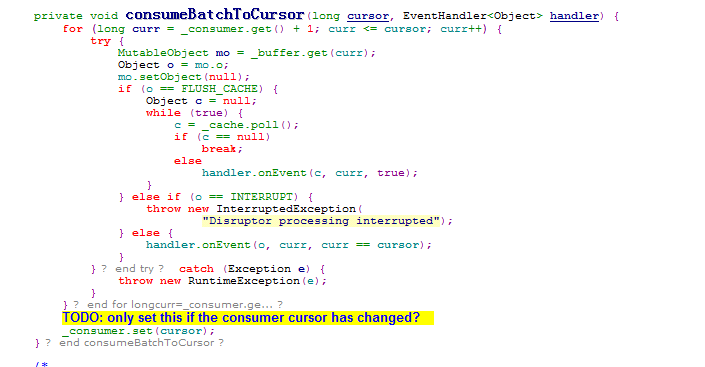
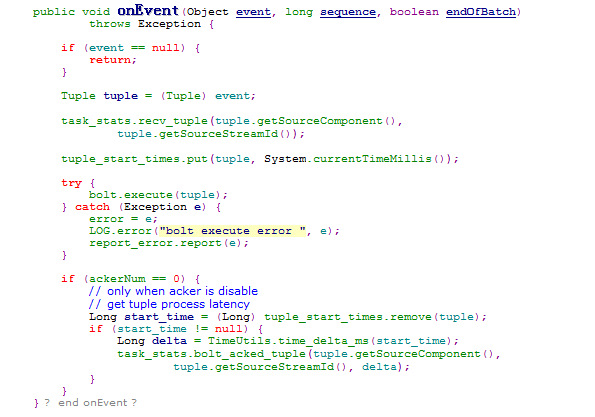
之后disruptorRecvQueue会通过consumeBatchWhenAvailable()和consumeBatchToCursor()来调用BoltExecutors的onEvent()对接受到的tuple进行处理。
在onEvent()中会调用bolt.execute(tuple)进行tuple的处理,即用户应用程序中bolt定义的处理内容。
Spout同理,见SpoutExecutors.java。
对于disruptorRecvQueue队列,它定义在了BaseExecutors(BoltExecutors和SpoutExecutors继承自这个类)中,通过RecvRunnable执行在一个独立线程中,这个线程需要维护这个接受队列,同时接受tuple并放入队列。RecvRunnabel线程中会循环调用recv()方法,当有tuple被收到后放入队列中。

在recv()中,通过ser_msg = puller.recv(0)得到接受内容,如果为空则返回,如果长度为1则是状态改变的消息,如果长度大于1则为tuple,序列化后返回由RecvRunnable放入队列。puller是一个IConnection接口,IConnection由zeroMQ、Netty等实现,即通过ZeroMQ或Netty等消息框架的recv()来获取tuple结果。

其实zeroMq的底层是利用了socket的方式实现。


